Schema del corso¶
Il corso è impostato sulla base delle fasi in cui tipicamente è organizzata un’analisi geografica mediante un software GIS, schematizzate nella figura sotto:
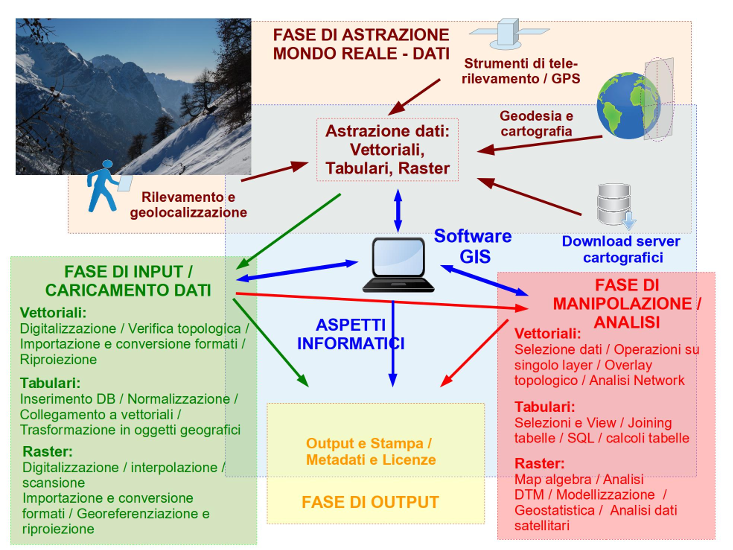
Di seguito viene invece riportata una breve descrizione dei diversi aspetti:
- Fase di astrazione dei dati del mondo reale: come le mappe cartografiche, un GIS può essere considerato un modo di rappresentare ed analizzare il mondo reale. L’astrazione del mondo reale in oggetti GIS (vettoriali, tabellari e raster) è una fase importante, che condiziona le successive: è importante comprendere le potenzialità e i limiti dei diversi modelli di rappresentazione. La prima parte delle dispense inquadra gli aspetti teorici della concettualizzazione GIS. In questa fase vengono anche brevemente richiamati i concetti di geodesia e cartografia, importanti per comprendere come si può rappresentare una superficie irregolare curva (la Terra) su una superficie piana;
- Aspetti informatici: l’astrazione in oggetti deve inoltre tener conto delle potenzialità e dei limiti del software utilizzato. Infatti, le sue potenzialità e funzionalità nelle diverse strutturazione degli oggetti reali (vettoriali, raster o tabellari) sono la base per la definizione del work-flow dell’analisi. Il software condiziona anche l’output e la vestizione dei dati;
- Fase di input: comprende il caricamento e la memorizzazione dei dei dati. Scopo di questa fase è quello di ottenere oggetti GIS strutturati correttamente e pronti per le analisi: è importante quindi conoscere come si prepara, si acquisisce o si corregge un determinato strato informativo;
- Fase di analisi e manipolazione: comprende la descrizione delle principali tecniche di analisi degli oggetti GIS. È spesso la fase più importante di uno studio GIS, che permette di ottenere nuove informazioni e le conclusioni dello studio, attraverso l’integrazione dei dati rilevati.
- Fase di output: fase finale di uno studio GIS, con produzione delle mappe finali con i risultati. Il lavoro prodotto può essere rilasciato per altri usi: importante quindi abbinarlo a metadati che precisano le caratteristiche e i limiti dei dati. Infine, le licenze chiariscono la possibilità e i limiti di utilizzazione sia del software, sia dei dati impiegati e del lavoro prodotto. Nel corso non sarà trattata la creazione di WebGIS.
Breve introduzione teorica¶
- In questa sezione sono introdotti gli aspetti teorici dell’analisi GIS:
- come è strutturato un sistema GIS;
- come viene modellizzata la realtà esterna in un GIS.
Cos’è un software GIS¶
Un GIS (Geographic Information System) è uno strumento computerizzato per cartografare, archiviare ed analizzare fenomeni geografici. La tecnologia GIS integra operazioni su database, analisi geografiche e statistiche, producendo output con le modalità di visualizzazione tipiche delle mappe. Può essere perciò considerato una banca dati (Information) geografica (Geographic) che permette l’analisi delle relazioni tra gli oggetti inseriti (System): uno strumento per la gestione e l’analisi dei dati geografici. La costruzione di mappe e l’analisi geografica non sono nuove (c’erano molto prima dei GIS) ma questi strumenti permettono una maggiore sofisticazione dei metodi tradizionali.
In italiano viene spesso utilizzato anche il termine SIT (Sistema Informativo Territoriale) che non è identico ad un GIS, mancando il riferimento alla parte geografica e cartografica. Un SIT può infatti essere costituito da una banca dati relativa al territorio, senza avere una rappresentazione cartografica dei dati inseriti.
Un GIS è formato in genere da 4 sottoinsiemi:
- input dei dati, per acquisire e trasformare i dati spaziali e tematici in forma digitale;
- archiviazione e il caricamento dei dati, per organizzare i dati, sia spaziali che tabulari, in una forma che permette l’aggiornamento e l’analisi; questa componente di solito utilizza un DBMS per i dati tabulari e un formato ad hoc per i dati spaziali (per esempio, gli shapefile);
- analisi e la manipolazione dei dati permette di definire e eseguire procedure sui dati spaziali o sugli attributi per generare informazioni derivate. In genere è considerato il “cuore del GIS” ed è la funzione distintiva rispetto ad altri database (eccetto ODBMS spaziali) e ai sistemi CAD (Computer-Aided drafting);
- output dei dati e il display permette di generare (sia sul display che come hard-copy) mappe e report tabulari, rappresentanti le informazioni derivate.
I dati in un GIS sono organizzati con uno schema verticale, cioè devono essere inseriti come layer tematici sovrapposti, sulla base del sistema di coordinate di riferimento (CRS).
Gli strati sovrapposti sono definiti in vario modo, anche in software non GIS, per esempio:
- layer, nome generico per strato, utilizzato da molti sotware tra cui AutoCAD (non è un GIS),
- theme, in ArcView,
- coverage, in Arc/Info.
La strutturazione verticale viene garantita dall’identico sistema di riferimento geografico (georeferenziazione), da creare prima dell’inserimento dati, alla prima apertura del progetto (vedi più avanti, settaggio CRS); in GRASS tale operazione viene detta creazione della location.
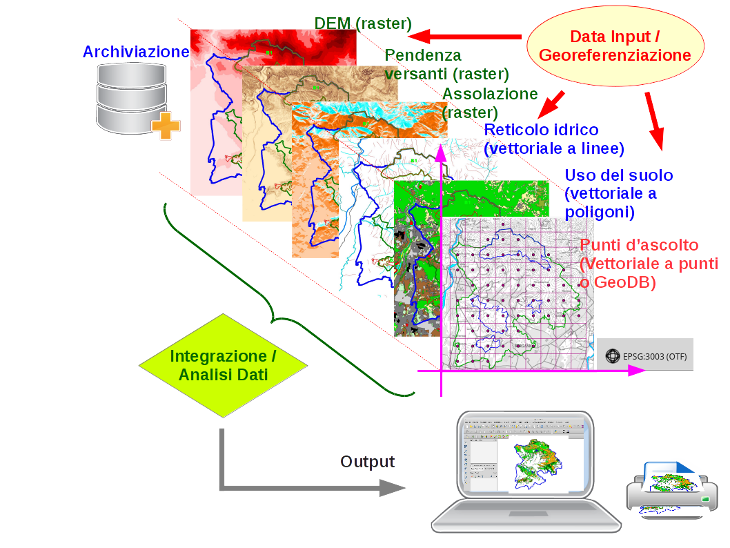
A differenza dei CAD, i software GIS devono essere in grado di trattare 3 tipologie di dato:
- il dato geometrico, cioè relativo alla tipologia geometrica degli oggetti (linee, punti, ecc.), alla dimensione e alla posizione geografica, registrata impiegando un sistema di proiezione reale;
- le relazioni topologiche, cioè relative alle relazioni reciproche tra gli oggetti;
- i dati informativi, cioè relativi alle informazioni associate agli oggetti geometrici.
Per trattare queste informazioni i GIS utilizzano principalmente 2 tipologie o modellizzazione: i vettori (generalmente utilizzati per dati discreti) e i raster (più idonei a rappresentare dati che variano in modo continuo).
- Infine, le principali funzioni analitiche dei GIS sono le seguenti:
- overlay topologico, cioè la sovrapposizione geografica degli elementi di due tematismi;
- query spaziali, cioè le interrogazioni sui dati a partire da criteri spaziali (vicinanza, sovrapposizione, ecc.);
- buffering, cioè la creazione di intorni di distanza fissa o variabile ad oggetti geografici;
- segmentazione, cioè la localizzazione di punti a distanze determinate rispetto all’inizio di un tema (in genere applicata a tematismi lineari);
- network analysis, con algoritmi di analisi delle reti, come ad esempio il percorso più breve tra due punti;
- spatial analysis, in genere usata con le tipologie raster e comprendente un’ampia serie di modelli matematici;
- analisi geostatistica, relativa all’analisi della correlazione spaziale delle variabili georiferite.
Alcune di queste funzioni saranno solo accennate nel corso (per esempio, l’analisi geostatistica), in quanto sono tipiche di un corso avanzato.
Archiviazione files (Working directory)¶
La struttura verticale indicata nel paragrafo precedente è anche un comodo modo di organizzare l’archiviazione dei files per un dato progetto di analisi GIS. Spesso infatti un’analisi comporta la creazione di molti files, di tipologia diversa (shapefiles, GeoTiff, script, ecc.)
Una tipica struttura di un progetto GIS può essere la seguente:
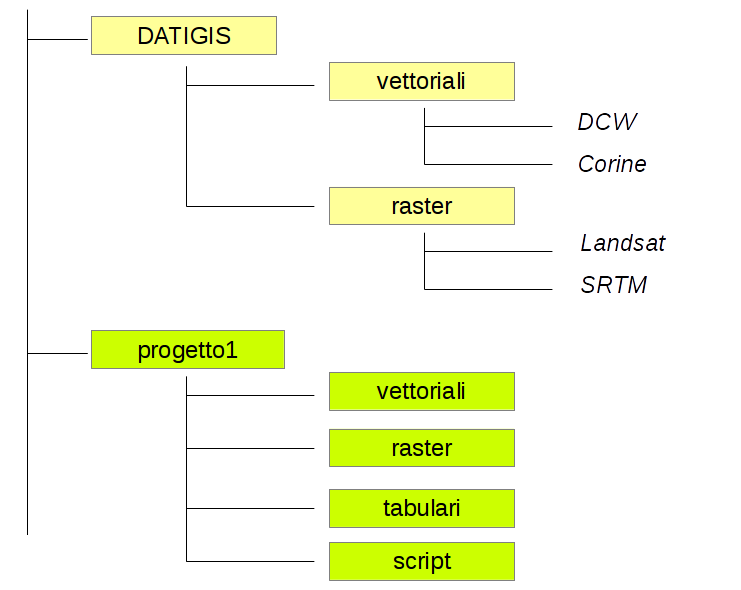
Nella directory DATIGIS sono archiviati i dati originali (scaricati da internet o ottenuti dagli enti che li hanno prodotti), organizzati per tipologia (vettori o raster) e aree geografiche (mondo, come la Digital Chart of the World, Europa, Italia, regioni varie). I dati in questa directory non vanno in genere modificati e vanno copiati nelle directory di progetto, dove viene realizzata l’analisi.
I vari progetti andrebbero infatti organizzati in directory separate, a loro volta suddivise in vettori, raster e, nel caso di un progetto molto dettagliato, in tabulari e script.
Astrazione dati reali in «oggetti» GIS¶
Le informazioni geografiche possono essere rappresentate con tipologie o modellizzazioni diversi, con vantaggi e svantaggi che vanno conosciuti già in fase progettuale, al fine di utilizzarle al meglio. Queste modellizzazioni (tipologie) sono:
- il modello vettoriale, esemplificabile in un disegno con punti, linee, poligoni;
- il modello raster, esemplificabile con un’immagine formata da pixel.
Gli attributi alfanumerici (tabelle di dati) possono essere collegate ai vettoriali o espresse come strati raster.
- Per esempio, prendiamo questa immagine, che presenta vari elementi geografici:
- un rifugio,
- un laghetto,
- la linea elettrica,
- la copertura vegetale,
- l’innevamento,
- l’altitudine, …

Questi elementi della realtà geografica possono essere modellizzati sia con la tipologia vettoriale (con dati tabulari associati, anche in forma di oggetti geografici), che in quella raster.
Le due modellizzazione (vettoriale e raster) possono essere archiviate nei GIS con 3 diverse modalità principali:
- con un formato per vettoriali, come punti, linee o poligoni, definiti nella loro localizzazione nello spazio (in riferimento ad un sistema di coordinate) e dai loro attributi (valori di un data caratteristica, spesso collegati ad una legenda);
- con un formato raster, come strati (layer) che rappresentano un attributo alla volta;
- in un formato tabellare (GeoDatabase), in cui gli oggetti geografici sono uno dei campi di un database, i cui record rappresentano gli attributi (i raster sono incorportati con sezioni (tiles) collegate ad un metadato).
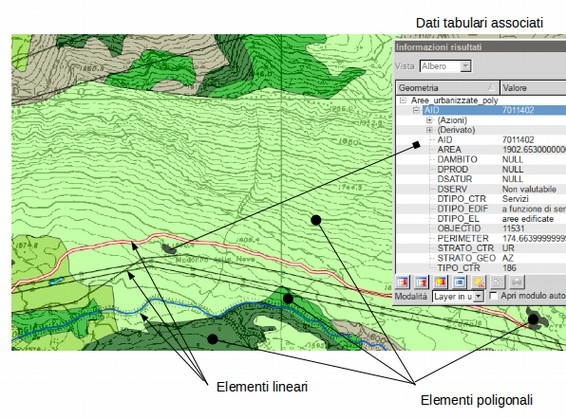
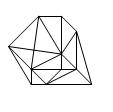
Esempio di formato vettoriale (con dati tabulati associati) dell’area mostrata in figura:
- linee e poligoni rappresentati separatamente
- più attributi associabili ad ogni oggetto
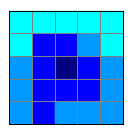
Esempio di formato raster (ultimo comando indica valore del pixel del laghetto):
- elementi lineari / poligonali possono essere rappresentati assieme.
- un solo valore associato (valore del pixel)
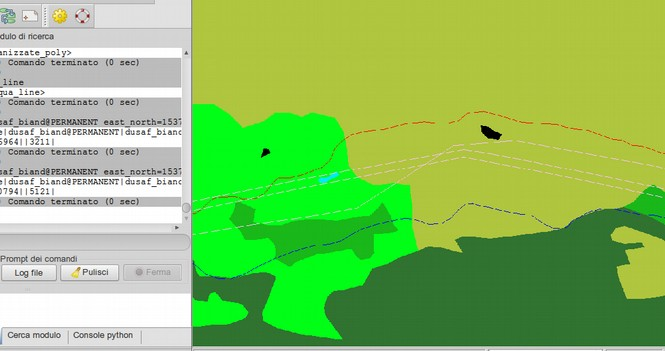
Esempio di formato tabellare. Nei geodatabase gli oggetti geometrici possono essere inseriti in un campo della tabella: nell’esempio (tabella di PostGIS), i campi geom_ll e geom_gb contengono oggetti binary corrispondenti alle localizzazioni inserite nel database, in due sistemi di riferimento diversi (latitudine / longitudine e Gauss-Boaga).
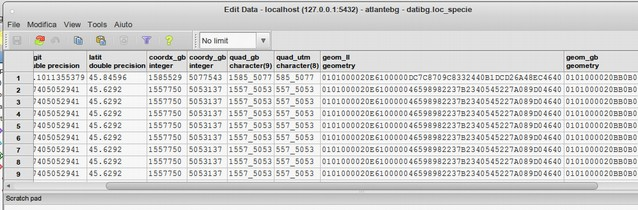
Lo schema sotto riassume le differenti modalità di archiviazione delle due tipologie:
Nella tabella sotto sono riassunte le caratteristiche delle diverse modellizzazioni. I punti, linea e poligono appartengono alla tipologia a confine definito; le superfici sono invece campi continui:
| Oggetto | Descrizione | Mod. Vettoriale | Mod. Raster | Mod. GeoDB |
|---|---|---|---|---|
| Punto (point, node) | Elementi associati ad una singola localizzazione nello spazio | Coordinate: (x,y) in 2D o (x,y,x) in 3D POINT / MULTIPOINT | ||
| Linea (arc, edge) | Elementi lineari, associati a catene di punti | Lista ordinata di coordinate: (x1,y1), (x2,y2), (x3,y3), (x4,y4) LINESTRING / MULTILINESTRING | ||
| Poligono (polygon, face) | Elementi che formano un’area chiusa | Lista di coordinate chiuse: (x1,y1), (x2,y2), (x3,y3), (x4,y4), (x1,y1) POLYGON / MULTIPOLYGON | ||
| Superficie | Vettoriale: TIN (set di punti triangolati), isoplete (es: curve di livello), matrice regolare di punti – Raster: rappresentazione continua di un valore, interpolato in maniera varia (kernel, kriging, IDW, spline) |



- È importante tenere presente che le tre tipologie di modellizzazione e archiviazione dei dati sono ottimizzate per aspetti diversi del trattamento dei dati:
- il modello vettoriale è preferibile per il trattamento di oggetti “discreti”, che hanno confini ben definiti e attributi collegabili in maniera univoca; inoltre è preferibile quando si è interessati ad una analisi delle relazioni topologiche (per esempio, l”overlay topologico o la network analysis);
- il modello tabellare (geodatabase) è ottimizzato per oggetti “discreti”, anche se può trattare oggetti raster; è preferibile quando si deve trattare una notevole mole di dati, sia come oggetti (numero di righe, quindi) che come attributi (numero di colonne);
- il modello raster è invece ottimizzato per il trattamento delle superfici e degli oggetti che non hanno confini definiti (campi a variazione continua); è inoltre preferibile utilizzarlo quando è necessaria una modellizzazione complessa di un fenomeno geografico.
 Esercitazione
Esercitazione
Scale di misura¶
L’astrazione degli oggetti reali non comprende solo la loro struttura geometrica, ma anche la tipologia degli attributi da associare. I diversi attributi associati ad un oggetto geografico possono essere infatti classificati, anche al fine dell’analisi statistica, in base ad una «scala di misura» idonea:
- scala di proporzione (ratio scale) o di rapporti, in cui gli attributi sono misurati su una scala che permette di confrontare gli intervalli e che ha uno zero non arbitrario. Esempio, la misura dell’altezza di un albero, la sua circonferenza alla base o il numero delle sue foglie: lo zero ha significato fisico (l’altezza 0) e le differenti misure sono proporzionali tra loro (esempio, la differenza tra 4 e 7 m è proporzionale a quella tra 126 e 129);

- scala di intervalli (interval scale), hanno intervalli costante e lo zero è arbitrario. Per esempio, la misura di temperatura in gradi Celsius e in Fahrenheit non ha lo stesso 0; ma esiste lo stesso intervallo tra 1°C e 4°C e tra 7°C e 10°C, così come tra 2°F e 5°F e tra 7°F e 10°F. Anche l’ora nel giorno, il mese nell’anno o i punti cardinali sono esempi di questa scala (lo zero, in tutti questi casi è arbitrario);
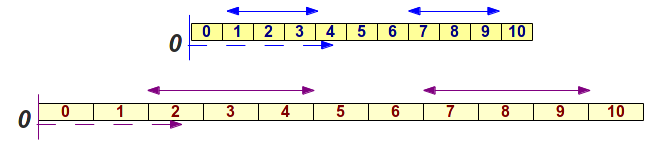
- scala ordinale (ordinal scale) o per ranghi, scale in cui i dati possono solo essere ordinati in qualche maniera, ma non è possibile dire la differenza tra dati; per esempio, si possono mettere in ordine (1,2,3,4,5 … oppure, a,b,c,d,e …) tra più leggeri e pesanti, oppure tra più grandi e piccoli, senza però misurare il valore su una scala di proporzione o di intervalli; in questo gruppo ci sono anche i dati ottenuti da punteggi soggettivi, per una determinata caratteristica (esempio, un test psicologico);
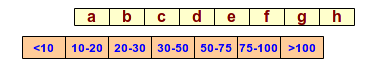
- scala nominale (nominal scale) o categoriale, è una scala qualitativa, non quantitativa, come il colore degli occhi, il sesso di un animale o il codice di un radio-collare. Le osservazioni campionarie sono basate sulla relazione di identità, cioè di appartenenza ad una determinata classe.

Le prime 2 scale sono quantitative e possono essere continue (cioè il valore misurato non ha “salti”, se non per la precisione dello strumento di misura, per esempio, la lunghezza delle corna di un trofeo può assumere valori come 10,01 … 10,1…10,0005, ecc) o discrete, in cui il valore è descritto da un numero intero (per esempio, il numero delle punte in un palco di cervo). Queste distinzioni sono importanti per il tipo di analisi statistica che può essere fatta (per esempio, parametrica e non parametrica). Le ultime 2 scale sono invece qualitative.
Esercitazione
Accuratezza e Qualità dei dati¶
Altra importante definizione da considerare è la qualità dei dati inseriti in un GIS e l’accuratezza della rappresentazione, anche se va tenuto presente che non sono stati definiti degli standard di riferimento consolidati.
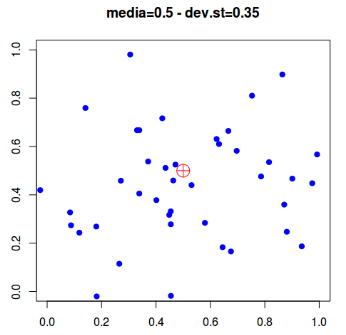
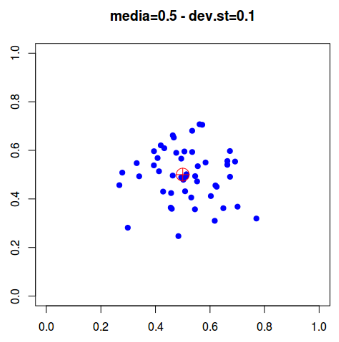
Importante tener presente la differenza tra accuratezza e precisione:
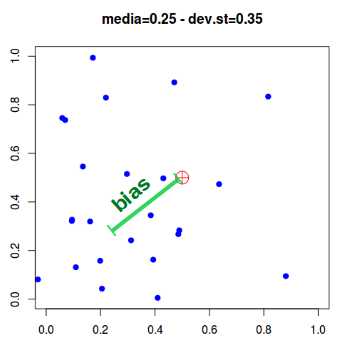
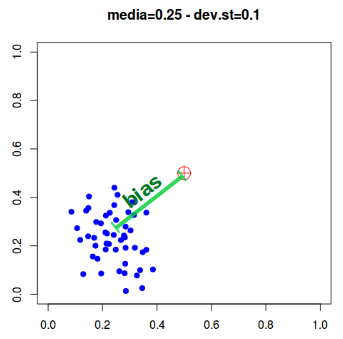
- Accuratezza: misura quanto simili sono le misure ripetute di una certo parametro non noto (esempio, il numero di coppie di cinciallegre nidificanti in un bosco). L’accuratezza è misurabile mediante il valore della deviazione standard;
- Precisione: è più difficile da calcolare e indica quanto vicina al valore reale è la stima ottenuta. In genere si ricorre al confronto tra metodi di rilevamento diversi per avere un’idea della precisione (se metodi diversi danno lo stesso valore, è probabile che questo sia preciso). Alla precisione è collegato il concetto di distorsione (bias) che esprime, in statistica, la stima della precisione.
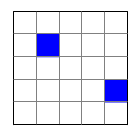
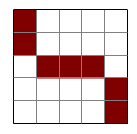
Nello schema sotto, il quadrato rosso rappresenta la misura di un ipotetico parametro da trovare; i segnali blu indicano invece i dati rilevati.
| Rilevamento non accurato né preciso | Accurato, ma non preciso |
|---|---|
 |
 |
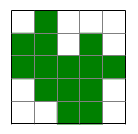
| Preciso, ma non accurato | Accurato e preciso |
|---|---|
 |
 |
Nei dati geografici ci sono 2 tipi di accuratezza e precisione: quella posizionale e quella degli attributi. Quella posizionale è relativa alla differenza tra le coordinate misurate e la vera posizione geografica e si divide in 2 componenti:
- assoluta, che considera il posizionamento dell’oggetto rispetto al sistema di riferimento usato (es: le coordinate del punto relativamente alla griglia UTM);
- relativa, che considera il posizionamento degli elementi uno relativamente all’altro (quest’ultima può essere più difficile da correggere ed è spesso più importante nei dati GIS).
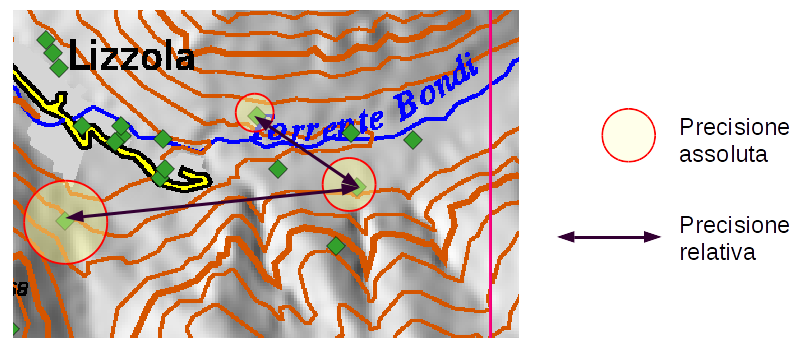
Esempio: Punti di rilevamento rilevati sulla carta: la precisione assoluta dipende dalla carta utilizzata o dallo strumento (GPS) utilizzato per il rilevamento e può essere diversa da oggetto ad oggetto. Precisione relativa: se si è utilizzato un GPS per rilevare i punti e una mappa cartacea per digitalizzare le strade e i fiumi, le misure tra oggetti saranno influenzate dalla diversa precisione dovuta ai due sistemi di rilevamento e input del dato (digitalizzazione e rilevamento GPS).
Anche l’accuratezza e la precisione di un attributo sono importanti: per esempio, determinare il confine di un’area di bosco misto da un bosco di latifoglie è spesso molto difficile e soggettivo. Questa decisione, per esempio, rende poco confrontabili mappe della stessa area fatte da persone diverse.
- Esempio: rilevamento di un punto d’ascolto dell’avifauna, individuato con il GPS:
- errore posizionale: rilevamento delle coordinate (variabile, ma in genere superiore a +/- 10-50 m)
- errori negli attributi: non tutte le specie presenti sono state rilevate o rilevabili, ecc..
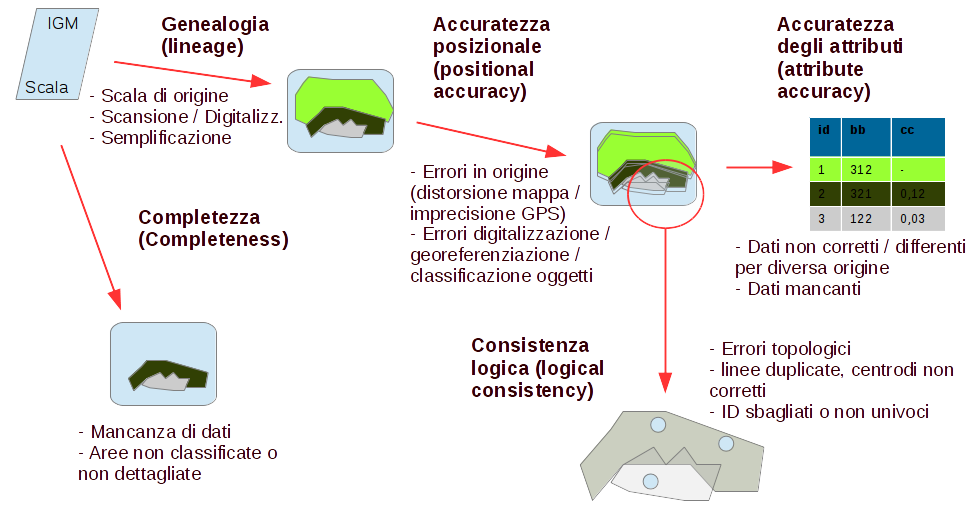
qualità: si può semplicemente definire come l’efficacia per un dato uso di uno specifico data-set. Poligoni digitalizzati per una scala possono essere non sufficienti per una scala di maggior dettaglio. Lo Spatial Data Transfer Standard (SDTS) ha identificato 5 componenti della qualità:
- genealogia (lineage): concerne la storia del dato, includendo l’origine, i contenuti, le specifiche del recupero del dato, la copertura geografica, il metodo di acquisizione (esempio: digitalizzazione o scansione), le trasformazioni applicate e l’uso di algoritmi idonei nella compilazione (per esempio, l’uso di semplificazione lineare degli archi);
- accuratezza posizionale (positional accuracy), divisi in errori intrinsechi (source error), presenti nel dataset originale (anche solo per distorsione della mappa di partenza a causa dell’umidità), ed operazionali (introduced error),cioè derivanti dalle operazione compiute all’interno del GIS (da errori di digitalizzazione o di georeferenziazione a errori di classificazione o di trasformazione dei dati);
- accuratezza degli attributi (attribute accuracy), concerne l’identificazione dell’attendibilità (o livello di omogeneità) in un data-set; possono essere causate da sorgenti dati indipendenti dall’originale immessa o da serie temporali non complete; possono verificarsi in questo caso o dati mancanti (missing data) o troppi dati per oggetto;
- consistenza logica (logical consistency), è relativa consistenza della struttura dei dati; è relativa alla presenza di errori topologici, come linee o confini duplicati, intersezioni non corrette, assenza di centroidi, ecc.; per quanto riguarda gli attributi,gli errori possono derivante da un non corretto identificatore unico (labels) assegnato durante la digitalizzazione. Si possono verificare casi di identificatori completamente sbagliati (quindi mancanza di collegamento) o di identificatori non unici (dati collegati in maniera scorretta a diversi oggetti contemporaneamente);
- completezza (completeness), include considerazioni su “buchi” nei dati, aree non classificate, o procedure di compilazione che possono aver eliminato dei dati. Il fatto che i dati GIS possono essere prodotti a qualsiasi scala rende questo aspetto molto importante, in quanto “dati completi” per una scala possono non esserlo per una scala di maggior dettaglio.
Per esempio, dati registrati a una scala di 1:20.000 hanno comunemente un’accuratezza posizionale di +/- 20 m. Questo significa che la localizzazione vera dell’oggetto può variare di 20 m in ogni direzione. Considerando che spesso l’uso dei GIS comporta l’integrazione di parecchi data-set, a differenti scale e qualità, si può facilmente comprendere come gli errori si possono propagare durante un procedimento di analisi GIS. Da qui l’importanza dei metadati, per valutare con che precisione è utilizzabile un dato.
Importante conseguenza: la migliore accuratezza di un output GIS può essere solo uguale a quella del peggiore tematismo coinvolto nell’analisi.
Inoltre, l’accuratezza dei dati diminuisce quando la risoluzione spaziale è più larga mentre la possibilità di aumentare gli errori aumenta con il numero di layer coinvolti nell’analisi.